スキャンされた PDF 文書
これは、次の達成基準に関連する実装方法である:
ユーザーエージェント及び支援技術に関する情報は、PDF テクノロジーノートを参照のこと。
このテクニックの目的は、視覚的にレンダリングされたテキストが、視覚的な表現によって読みやすさが損なわれることなく、理解できる形式で表示されるようにすることである。
テキストをスキャンした画像で構成される文書は、文書のコンテンツが画像であって検索可能なテキストではないので、本質的にアクセシブルではない。支援技術で語句を読み上げたり抽出したりすることはできない。ユーザーはテキストを選択、編集、サイズ変更またはリフローすることも、テキストや背景色を変更することもできない。作成者は PDF を操作してアクセシビリティを実現することができない。
これらの理由から、作成者はテキストの画像ではなく実際のテキストを使用し、Microsoft Word や Oracle Open Office などのオーサリングツールを使用してコンテンツを作成し PDF に変換すべきである。
作成者がソースファイルやオーサリングツールを利用できない場合は、光学式文字認識(OCR)を使用することで、テキストをスキャンした画像を PDF に変換できる。その後で、Adobe Acrobat Pro を使用することでアクセシブルなテキストを作成できる。
この事例は Adobe Acrobat Pro の場合を示している。同様の機能を実行するソフトウェアツールは他にも存在する。他のソフトウェアツールのリストについては、「アクセシビリティがサポートされている PDF オーサリングツール」を参照のこと。
この事例では、テキストをスキャンした、単純な 1 ページの画像を使用している。文書に実際のテキストが確実に格納されるようにするには、以下の手順を実行する。
可能な限り高い解像度で文書をスキャンして、OCR のパフォーマンスを向上させる
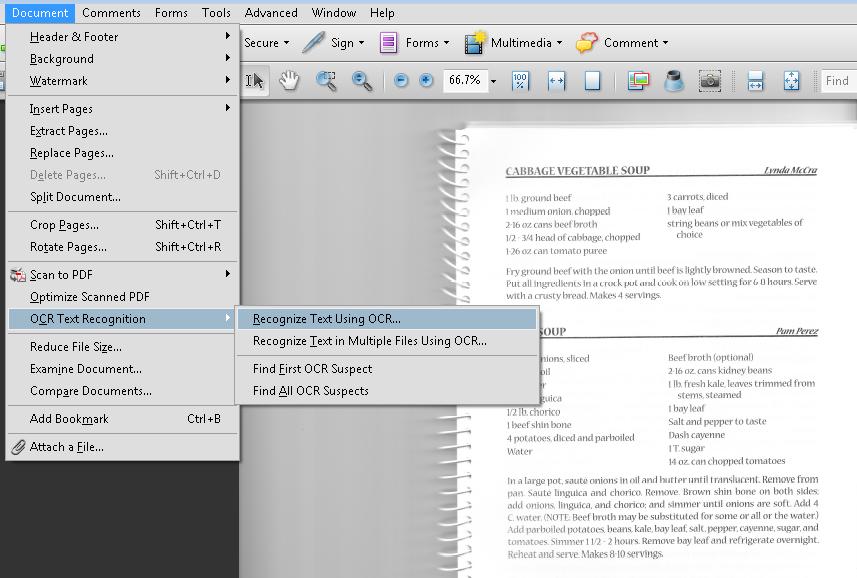
スキャンされた文書を Acrobat Acrobat Pro に読み込む。文書構造を使用 > OCR テキスト認識 > OCR を使用して[テキストを認識]を選択する
次のダイアログボックスで、「ページ」(1 ページのみ変換する場合は「現在のページ」)の下の「すべてのページ」ラジオボタンを選択し、[OK]を押下する
「設定」リストで「編集」を選択する。次のダイアログボックスで、「PDF の出力形式」ドロップダウンリストの「テキストとグラフィック」を選択する。これはアクセシビリティを確保するために重要である
解像度とテキストの明瞭度に応じて、OCR が単語や文字のイメージを実際のテキストに変換する。Acrobat Pro で認識されないテキストは、「不明テキスト」と表示される。これは、正しく認識されなかったことが疑われるテキストエレメントである
不明テキストを修正するには、文書構造を使用/OCR テキスト認識/最初の不明テキストを表示を選択する。Acrobat Pro では不明テキストが 1 つずつ表示され、不明テキストは Acrobat Pro TouchUp ツールを使用して修正できる
アドバンスト > アクセシビリティ > 文書にタグを追加を実行する
アドバンスト > アクセシビリティ > フルチェックを実行して、アクセシビリティをテストする
注記: 別の方法として、文書構造を使用 > OCR テキスト認識 > すべての不明テキストを表示を使用し、すべての不明テキストを同時に表示して編集を素早く行うこともできる。
次の画像は、Adobe Acrobat Pro に表示されている、スキャンされた 1 ページの文書を示している。
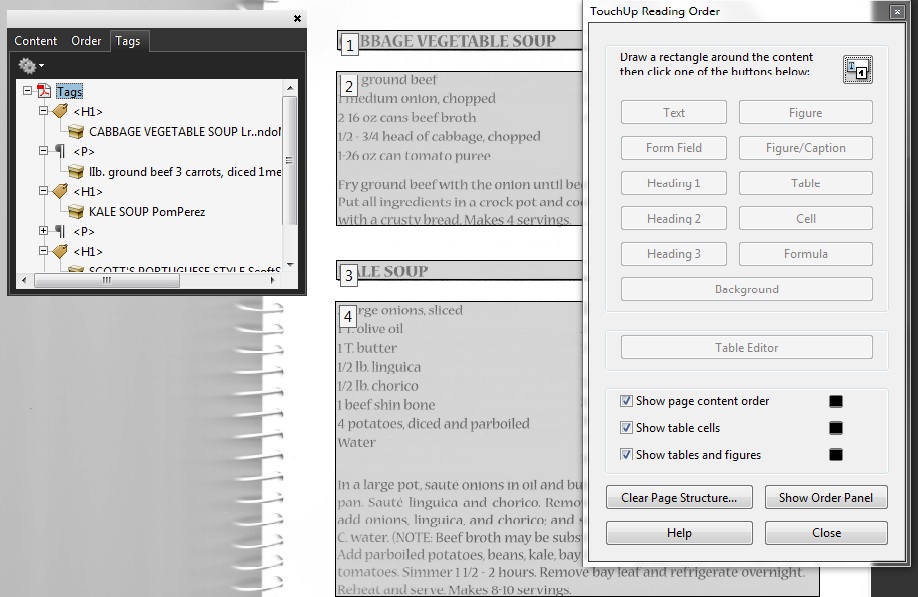
次の画像は、文書にタグを追加した後で変換されたコンテンツを示している。コンテンツに正しくタグ付けし、最終的に意図した文書を得るには、TouchUp 読み上げ順序ツールとタグパネルを使用する必要があると考えられる。この事例では、らせん綴じの本の画像がタグ付けされ変換されている。TouchUp 読み上げ順序ツールを使用することで、画像が(装飾的な)背景画像として非表示になっている(「PDF4:PDF 文書の Artifact タグによって装飾的な画像をタグ構造から削除する」を参照のこと)。レシピのタイトルは、第 1 レベルのヘッダとしてタグ付けされている。
注記: Acrobat Pro では、ファイルに対して OCR を実行すると自動的にタグが追加される場合がある。
この事例のサンプルとして、実際のテキストを生成するサンプル(PDFファイル) と OCR の実行結果サンプル(PDFファイル)がある。
この参考リソースは、あくまでも情報提供のみが目的であり、推薦などを意味するものではない。
OCR を使用して各ページをテキストに変換した場合には、次のいずれかの方法を使用して、PDF が正しく変換されたことを確認する。
スクリーンリーダーまたは読み上げ機能があるツールを使用して PDF 文書を読み上げると、すべてのテキストが正しい順序で読み上げられている
文書をテキストとして保存すると、変換されたテキストが完全であり、正しい読み上げ順序になっている
変換されたコンテンツを表示できるツールを使用して PDF 文書を開くと、すべてのテキストが変換されて正しい読み上げ順序になっている
アクセシビリティ API を通じて文書を表示するツールを使用して、すべてのテキストが変換されて正しい読み上げ順序になっていることを確認する
1. を満たしている。
注意: この実装方法が「達成基準を満たすことのできる実装方法」の一つである場合、このチェックポイントや判定基準を満たしていなければ、それはこの実装方法が正しく用いられていないことを意味するが、必ずしも達成基準を満たしていないことにはならない。場合によっては、別の実装方法によってその達成基準が満たされていることもありうる。